Architecture des machines
- Introduction
- Architecture des ordinateurs
- Représentation des informations
- Calcul binaire
- Passage binaire en décimal
- Passage décimal en binaire
- Représentation des nombres négatifs en binaire
- Complément à 1
- Avantage : le codage s'éffectue en une seul étape.
- Inconveniant : l'addition se fait en deux étapes : il faut rajouter la retenue au resultat (si elle existe...)
- Complément à 2
- Avantage : l'addition s'éffectue en une seul étape.
- Inconveniant : le cogade s'éffectue en deux étapes.
- Codage de l'information
- Codage alphanumérique
- Code ASCII
- Code HOLLERITH
- Code UNICODE
- Les nombres réels
- 3 représentations possibles
-
Virgule fixe : toujours le même
nombre de chiffres après la virgule
- Couple (numérateur, dénominateur) :
- Avantage : les calculs sont justes.
- Inconvenient : pas de représentation de réels.
- Virgule flottante : c'est le plus utilisé
- Un nombre est représenté par :
- le signe S
- sa mantisse M
- son exposant E
- Normalisation de la représentation
- La mantisse sera dans l'intervalle [ 1,10 [
- La norme IEEE 754 définit la manière de représenter en m´moire les nombres à virgule flottante normalisés
- Les nombres normalisés ont une matisse entre [ 1,10 [. Le seul chiffre à gauche de la virgule sera 1 en binaire. (sauf pour 0)
- La norme IEEE 754 définit la manière de représenter en m´moire les nombres à virgule flottante normalisés
- 3 représentations
- Simple précision sur 32 bits
- mantisse sur 23 bits
- exposant sur 8 bits
- signe 1 bit
- Double précision sur 64 bits
- mantisse sur 52 bits
- exposant sur 11 bits
- signe sur 1 bit
- Pour faciliter les opérations de comparaison entre exposants, on utitlise des exposants positifs ou nuls.
- => On utilise une représentation avec excès de 127 pour la simple précision. (1023 pour la double précision).
- Représentation d'un nombre IEEE754
(-1)S.(1+M).2E-127
- Couple (numérateur, dénominateur) :
-
- Exemples
- Exemple 1
-
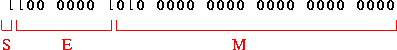
- S= 1 (bit de poids fort)
- E= 100 0000 1 = 129
- M= 010 0000 0000 0000 0000 = (0,01)2 = (1 * 2-2)10 = (0,25)10
- =>Représentation :
(-1)1.(1+0,25).2129-127 = (-1)1.(1,25).22 = -1,25 . 22 = -5 - E= 100 0000 1 = 129
- Exemple 2
- (432)10 en IEEE754 ?
- S= 0 car 432>0
- Le reste = 28*1,6875 car 432=256*1,6875
- => E=127+8=135 = 10000111
- => M=0,6875 = 0,5 + 0,1875 = 0,5 + 0,125 + 0,0625 = 2-1 + 2-3 + 2-4 = 0,10110000000000000000000
- => (432)10 = 0100 0011 1101 1000 0000 0000 0000 0000
- Le reste = 28*1,6875 car 432=256*1,6875
- Logique combinatoire et séquentielle
-
-
- Algèbre de Boole
-
- Les fonctions élémentaires
-
- Les fonctions unaires
- Les fonctions binaires
identité
négation : opérateur NON (NOT)


- Les fonctions logiques
Une fonction logique complexe peut se matérialiser par un circuit combinatoire.

- Multiplexeur
C'est un circuit combinatoire qui accepte en entrée plusieurs données (signaux logiques), et n'autorise la sortie que d'un seul d'entre eux. (appelé aussi Sélecteur de données).
- Démultiplexeur
C'est un circuit combinatoire qui accepte une ligne d'entrée et de nombreuses lignes de sortie.
- Codeurs, Décodeur, Transcodeur
- decodeur
fait correspondre à un code en entrée (à n_lignes), une seule sortie active (=1)
- codeur
à une entrée active (=1), il fait correspondre en sortie un code sur n_lignes.
- transcodeur
fait correspondre à un code A en entrée un code B en sortie
- Horloges
L'ordre d'apparition des variables dans les systèmes logiques peut être important. Pour respecter des relations de séquentialité contraignantes, on utilise des horloges qui assurent la synchronisation temporelle.
Une horloge est un système logique qui émet régulièrement une suite d'impulsions. Il se peut que plusieurs évènements se produisent durant la même impulsion. On réduit donc le cycle d'horloge grâce à un circuit de retardement.

- Circuits Séquentiels
Les Circuits Combinatoires sont des circuits idéaux. Il n'y a pas de délais, et pas de rétroaction (i.e pas de retour dans les entrées et les sorties).
Les Circuits Séquentiels possedent des rétroactions et les signaux de sortie ne dépendent pas uniquement des entrées mais aussi de leurs séquences.




- Bascules
- Bascule RS
- Bascule JK
- Bascule D
- Variantes des bascules D
- LATCH
mémorisation au top de l'horloge.

- FLIP-FLOP
pour des raisons de précision, les flip-flop mémorisent selon les transitions, c'est-à-dire les passages de 0 à 1 (phases montantes) ou de 1 à 0 (phases descendantes).

- LATCH

Ne présente plus d'indétermination quand R=S=1

Le cas R=S=1 est résolu en faisant en sorte qu'il ne se présente jamais.

D est une mémoire de 1 bit, ce bit mémorisé étant à tout moment disponible sur la sortie.
La mémorisation prend effet dès qu'une impulsion arrive de l'horloge.
Les variables ne prennent que les valeurs 0 ou 1
- Les Registres
Un registre est un assemblage de cellules de base qui jouent un rôle de cellules mémoires capables de conserver une information binaire sur leur sortie.
2 types de registres
Les registres à cellules non interconnectées, qui servent pour le stockage des données.

Les registres à décallage : la sortie d'une cellule mé:moire est reliée à l'entrée de la suivante.

- Les mémoires
C'est un dispositif capable d'enregistrer, conserver, et restituer des données.
- HIERARCHIE
On peut les classer selon certaines caracteristiques :
- capacité
- temps d'accès
- coût par bit


- ANTEMEMOIRE
C'est la mémoire cache dans le microprocesseur
- coût élevé
- capacité faible
- temps d'accès très faible
- capacité faible
Tampon entre le microprocesseur et la mémoire centrale.
- MEMOIRE CENTRALE
C'est l'organe principal de rangement des informations utilisées.
- coût relativement bon marché.
- temps d'accès supérieur à l'antemémoire.
- MEMOIRE TAMPON
Accélère les transferts de données entre la mémoire centrale et la mémoire de masse.
- MEMOIRE DE MASSE
Concerne les périphériques de stockage :- disques
- cartouches
- bandes...
- La mémoire centrale
Y sont stockées les informations que l'on utilise et une partie du systè du systè d'exploitation.
On accède aux données par leurs adresses.- accès direct ou accès aléatoire appelé RAM : Random Access Memory
- par opposition à ROM : Read Only Memory
- On distingue deux types de RAM:
-
SRAM : Statique : un point mémoire = 1 bascule : très rapide.
- DRAM : Dynamique : nécéssite un rafraîchissement : moins rapide.
- Le processeur
C'est une structure qui contient divers circuits qui éffectuent des opérations logiques et arithmétiques. C'est aussi la partie de l'ordinateur qui exécute les opérations indiquées par les instructions.
C'est l'Unité de Commande (UC) qui pilote le processeur en lui envoyant, par exemple, un certain nombre de commandes à exécuter. En réponse, le processeur peut envoyer des informations concernant la commande (résultat, retenue,etc...).
Il contient plusieurs éléments dont l'UAL (Unité Arithmétique et Logique), et plusieurs registres.
ATTENTION : Ne pas confondre le microprocesseur qui est lui-même un processeur associé à une UC (i.e c'est une unité de traitement complet).
- L'unité arithmétique et logique(UAL)
Unité combinatoire permettant de réaliser plusieurs fonctions sur un couple d'entrées.
les fonctions arithmétiques +,-,...
les fonctions logiques ET, OU,...

A et B : Données d'entrées sur n-bits
F : Sortie sur n-bits
Cin : retenue entrante
Cout : retenue sortante
Fonction : sur le bit, indique une des 2k fonctions possibles.
- Exemple de fonctions sur 3 bits S2 S1 S0

L'UAL est constitué en général de 4 bits qui ont le rôle de flags :
V : permet de détecter un dépassement (overflow) pour la rprésentation d u résultat.
Z : permet de détecter les résultats nuls.
S :permet de détecter le signe du résultat.
C : la retenue sortante (Carry).
- Le décaleur
Effectue différents décalages.
Le type de décalage est donné par un nom de commande.

a3 a2 a1 a0 à droite à gauche LOGIQUES 0 a3 a2 a1 a2 a1 a0 0 ARITHMETIQUES a3 a3 a2 a1 a3 a1 a0 0 CIRCULAIRES a0 a3 a2 a1 a2 a1 a0 a3 CIRCULAIRES avec C (retenue) C a3 a2 a1 a2 a1 a0 C
- L'unité centrale de traitement(CPU)
C'est l'élément moteur de la machine qui exécute et interprète les instructions du programme.- On distingue deux parties:
- le processeur
- l'unité de commande(UC)
- l'unité de commande
C'est l'ensemble des dispositifs coordonnant le fonctionnement de l'ordinateur pour lui faire exécuter la suite d'opérations spécifiées dans le programme.
L'unité de commande dirige le fonctionnement de toutes les autres unités : processeur, mémoire, E/S grâce à des signaux de cadence (horloge) et des commandes.
- Fonctionnement:
- l'UC va chercher une instruction en mémoire centrale en envoyant une adresse et une commande.
- l'instruction lui est transféré.
- l'UC décode l'instruction et détermine la suite d'opérations à effectuer.
- l'UC cherche les données à traiter et les transfère vers le processeur.
- la suite d'opérations est utilisée par l'UC pour générer les signaux nécessaires au processeur pour exécuter l'instruction.
- Les données en sortie du processeur sont transférées en mémoire.
- le Compteur Ordinal (CO):registre contenant l'adresse en mémoire où est stockée l'instruction
- le Registre Instruction (RI):reçoit l'instruction à exécuter
- le Décodeur:détermine l'opération à effectuer
- le Séquenceur:génère les signaux de commande
- l'Horloge:permet la synchronisation.

Légende:
1 :Le CO transfère l'adresse de l'instruction vers le Registre Adresse(RA).
2 :La mémoire transfère l'instruction vers le Registre Mot(RM).
3 :L'instruction est envoy&eacue;e au Registre Instruction(RI).
4 :L'adresse de l'opérande est envoyée dans le RA.
4' :Le code de l'opération est envoyé au décodeur.
5 :Le décodeur détermine le type d'opération et le transmet au séquenceur.
6 :Le séquenceur fait incrémenter le CO.
A :Le séquenceur envoie des signaux à la mémoirepour lire l'opérande à l'adresse stockée dans le RA et la faire parvenir dans le RM.
B :Transfert du contenu du RM vers le processeur entant que données externes.
C :L'opération est effectuée via les mots de commandes du séquenceur.
Synchronisation des opérations
Les circuits qui synchronisent et controlent toutes les opérations de l'ordinateur sont dans l'UC.
Le cycle de base (cycle machine) est généré par l'horloge. Un cycle instruction (=cycle recherche +cycle exécution) dépend du type d'opération et peut s'étendre sur plusieurs cycles machines.

Séquenceur:automate générant les signaux de commande nécessaires pour actionner et contrôler les unités participant à l'exécution d'une instruction.
- DRAM : Dynamique : nécéssite un rafraîchissement : moins rapide.
Présentation du système d'exploitation
- Introduction
- Définition:
- Historique
- les débuts (1945-1955)
- ENIAC
- 20 tonnes, 160 m2
- calculateur unique : une équipe pour tout faire
- pas de mémoire
- un programme à la fois
- méthode de chargement des données : cartes perforées.
- transistors (1955-1965)
- Invention de la mémoire
- industrialisation et construction
- programmation :
- écriture des cartes par le programmeur
- chargement des cartes compilateur (par l'opérateur)
- chargement des cartes programme
- création du code intermédiaire : l'ASSEMBLAGE
- chargement des cartes assembleur
- création des codes machine
- exécution du programme.
- chargement des cartes compilateur (par l'opérateur)
- Problème : à chaque erreur, le programmeur doit faire un listing de l'image mémoire. Cela entraine une perte de temps.
- Solution :
- traitement par lots (bacth processing) : On regroupe et on exécute ensemble les travaux similaires.
- moniteur résident : enchaine automatiquement les travaux : création d'un nouveau type de cartes qui donnera des instructions au moniteur (charger, exécuter,...)
- Le moniteur est l'ancêtre des systèmes d'exploitation. (la mémoire est d'ailleurs découpée en deux parties : moniteur et utilisateur.
- VSLI et multiprogrammation (1965-1980)
- Circuits intégrés :
- réduction des coûts
- évolution rapide
- vente aux entreprises
- Les disques magnétiques
Multiprogrammation : plusieurs programmes en mémoire; si le programme en cours d'exécution demande une opération d'entrée/sortie (va voir le disque dur, par exemple...), alors un autre programme s'exécute en même temps;- Circuits intégrés :
- les débuts (1945-1955)
- UNIX
- Points forts:
- Points faibles:
- Achitecture d'UNIX
- Achitecture du noyau
- Le système de gestion des fichiers (SGF)
- Qu'est-ce qu'un fichier ?
- Un fichier UNIX est une suite d'octets (finis).
- Il est matérialisé sur le disque par une inode et des blocs disque.
- Il est matérialisé sur le disque par une inode et des blocs disque.
- le nom du propriétaire
- le nom du groupe du propriétaire
- le type de fichier
- les droits d'accès
- la date du dernier accès
- la date de dernière modification de l'inode
- la taille du fichier
- les adresses des blocs disque contenant le fichier.
- le nom du propriétaire
- Différents types de fichiers
- Standard
- tout ce qui est manipulé et créé par les utilisateurs (.txt, les exécutables,...)
- Spéciaux
- ne sont manipulables que par le système, ou via le
système. Ils gèrent les périphériques, la
mémoire... On peut ranger aussi les répertoires. on
distingue:
- les fichiers physiques : /dev
character devices : terminaux(clavier et ecran),imprimantes...
blocks devices : mémoire, disques, bandes...
- les fichiers logiques :
liens symboliques
les pseudo-terminaux
les sockets
les tubes
- les catalogues.
C'est une arborescence organis&eaucte;e comme un graphe acyclique, avec une racine /.
Le répertoire courant peut être appelé .
Le répertoire père est appelé ..
On peut acceder à n'importe quel endroit de l'arborescence par une référence relative ou absolue.
absolue : on donne tout le chemin pour s'y rendre
relative : on y va nœud par nœud à partir du point où on est. - les fichiers logiques :
- les fichiers physiques : /dev
- Organisation des disques
- Boot Block : utilisé au chargement
du système.
- Super Block : contient toutes les
informations générales du disque logique.
- Inode List : table des inodes.
On peut avoir plusieurs disques logiques sur un disque physique.

Quand un fichier est en cours d'utilisation, son inode contient trois nouveaux champs :
- son statut
- son numero de disque logique
- son numero d'inode sur le disque.
- Adressage des blocs dans les inodes
Le système d'adressage des blocs dans les inodes consiste en 13 adresses de bloc :- 10 à adressage direct sur les blocs de donées
- 3 à adressage indirect vers des blocs contenant des adresses à 1,2 ou 3 degré d'indirection.

Ce système permet d'économiser sur la taille des inodes, tout en permettant un temps d'accès rapide aux petits fichiers(les majoritaires), tout en permettant d'avoir de gros fichiers.
- Allocation des inodes d'un disque
Elle est réalisée en recherchant dans la liste des inodes une inode libre. Pour accelerer cette recherche, dans le Super bloc, est géré un tampon d'inodes libres et est conservée l'indice de la première inode libre.
- Allocation des blocs-disques
Pour allouer plus facilement, on les a chaînés. Ce chainage est réalisé ar blocs d'adresses pour accelerer les accès et profiter du buffer-cache. Il existe un bloc d'adresses dans le Super bloc qui est utilisé par l'allocateur de blocs.
- Le Buffer Cache
- Définition
- -les disques sont très lents par rapport à la CPU,
donc un noyau se chargeant des Entrées/Sorties serait trop lent
et surtout l'unité de traitement serait utilisée
à un trop faible pourcentage. Pour réduire les accès
disque :
- on bufferise les commandes d'écriture et de lecture et on
fait un accès disque uniquement pour une quantité de
données raisonnable.
- on écrit des données uniquement lorsqu'elles ne sont plus modifiées.
- Avantages et inconvénients
- Avantages
- Accès uniforme au disque : le noyau interagit uniquement
avec le buffer cache, quelles que soient les données.
- Utilisation des Entrées/Sorties plus simple pour l'utilisateur.
- Réduction du trafic disque donc augmentation des ressources disponibles (ne pas trop réduire la taille de la mémoire centrale à cause des tampons).
- protection contre les écritures concurrentes.
- Utilisation des Entrées/Sorties plus simple pour l'utilisateur.
- Inconvénients
- L'écriture différée occasionne la perte de données en mémoire an cas de crash machine. Les données non encore écrites sont perdues.
- Le buffer cache nécéssite une recopie (de la zone utilisateur au cache, et inversement) pour toute Entrée/Sortie. Si ces tranferts sont nombreux, cela ralentit les Entrées/Sorties.
- Structures de données
- Statut des blocs cache du buffer cache
- Verrouillé : accès
réservé à un processus.
- Valide : données contenues dans le bloc valide.
- A écrire : données à écrire sur un disque avant de réallouer le bloc.
- Actif : le noyau est en train de lire ou d'écrire.
- Attendre : un processus attend que ce bloc soit libéré
- Valide : données contenues dans le bloc valide.
- La bibliothèque standard C
- Les descripteurs de fichiers
- stdin : entrée standard (par défaut le clavier)
- stdout : sortie standard (par défaut l'écran)
- stderr : sortie d'erreur standard (par défaut l'écran)
- Ouverture de fichier
- filename : référence relative ou absolue du fichier à ouvrir.
- type : mode d'ouverture du fichier :
- r : ouverture en lecture en DEBUT de fichier
- w : ouverture en écriture en DEBUT de fichier (avec écrasement)
- a : ouverture en écriture en FIN de fichier (ajoint)
- w : ouverture en écriture en DEBUT de fichier (avec écrasement)
- r : ouverture en lecture en DEBUT de fichier
- r+, w+, a+ : même mode que ci-dessus, mais avec ECRITURE et LECTURE.
- Écriture/Lecture non formaté
- => avantage : rapidité
- => inconvénient : données illisibles si le type est inconnu.
- int fwrite(void * add, size_t ta,
size_t nbobjets, FILE * f)
écrit nbobjets de taille ta situé à l'adresse add dans le fichier f.
exemple
- int n[3];
- fwrite (n,sizeof(int),2,f);
copie les deux premières cases du tableau n.
exemple
char c; FILE * f; f=fopen("fichier.txt","w+"); getchar (c); while(c != 'q') { fwrite(&c,sizeof(char),1,f); getchar (c); }
fwrite renvoie 0 en cas d'erreur.
- int n[3];
- int fread(void * add, size_t ta,
size_t nbobjets, FILE * f)
lit nobjets de taille ta dans le fichier f et les range à l'adresse mémoire add.
Si on essaye de lire au delà du fichier, fread renvoie 0.
exemple
int n[2]; fread(n,sizeof(int),2,f); - Accès séquentiel
- séquentiel (bandes)
les informations sont traitées dans l'ordre où elles apparaissent.- direct (disque)
On se place directement à l'endroit où se trouve l'information.- séquentiel (bandes)
- Manipulation du pointeur de fichier
- int fseek(FILE * f, long pos, int direction);
SEEK_SET : placement sur l'octet pos
SEEK_CUR : positionnement pos octets apr`s la position courante.
SEEK_END : placement pos octets après la fin du fichier.
exemple
fseek(f, 5, SEEK_SET) : on se place sur le 5ème de f.
fseek(f, 3, SEEK_CUR) : on se place sur le 8ème de f.
fseek(f, -2, SEEK_END) : on se place sur à deux octets avant la fin.
- int ftell(FILE * f) : retourne la position du pointeur du fichier.
exemple
fseek(f, 0, SEEK_END); printf("taille du fichier=%d", ftell(f));- void rewind(FILE * f) : idem à fseek(f, 0, SEEK_SET);
- int fclose(FILE * f) : fermeture de fichier.
Ferme le fichier, libère le tampon qui lui a été alloué, libère le descripteur.
- int fseek(FILE * f, long pos, int direction);
Les fichiers sont de type FILE, définis dans la bibliothèque stdio.h. C'est une structure contenant tout ce qui est nécessaire (les informations) à la manipulation d'un fichier ouvert.
Toutes les fonctions de manipulation de fichiers prennent comme premier argument une variable de type FILE (plus exactement un pointeur sur une variable).
Il existe 3 descripteurs prédéfinis :
FILE fopen(const char * filename, const char * type)
FILE *f;
f=fopen ("/home/usr/note.txt","r");
ouvrir le fichier nommé /home/usr/note.txt en lecture en début de fichier.
La fonction renvoie un descripteur de fichier si elle s'est exécutée correctement, ou sinon renvoie NULL.
Le contenu d'une zone mémoire est recopié tel quel dans le fichier.
Fait partie de deux types d'accès aux données :
C'est un entier qui permet de spécifier où se fera la prochaine opération de lecture/écriture.
On peut le manipuler avec :
- Appels système du SGF
Ce sont les systèmes d'entrées/sorties de bas niveaux (gérés par le noyau).
Les différents appels système :
- open/event
- read/write
- fseek : déplacement de pointeurs de fichier
- dup/dup2 : copie d'ouverture de fichier.
- close
- read/write
- open
- f : nom du fichier
- mode : mode d'ouverture
- O_RDONLY
- O_WRONLY
- O_RDWR
- O_APPEND
- O_CREAT
- O_EXCL
- O_WRONLY
- permis : positionne les droits du fichier.
exemple
open("f", O_RDWR | O_CREAT, 066);
table de gestion de fichiers 
Déroulement interne d'un open:- Le système détermine l'inode du fichier à ouvrir.
- Soit l'inode est dans la table des inodes en mémoire, soit elle n'y est pas, le système alloue alors une variable entrée et recopie l'inode du disque.
- Vérification des droits d'accès.
- Allocation d'une entrée dans la table des fichiers ouverts, positionnement du curseur de lecture/écriture.
- Allocation d'une place dans le tableau des descripteurs.
- Envoi au processus du numero de descripteur.
- creat
int creat(char * f, int permis);
Déroulement interne- Le système détermine l'inode du catalogue où va être créé le fichier.
- S'il n'y a pas d'inode pour le fichier
- -> vérification des droits du catalogue
- -> allocation du nouvel inode
- -> allocation d'une entrée dans la table des inodes en méeacute;moire.
- -> vérification des droits du catalogue
- S'il y a une inode :
- le noyau lit l'inode et vérifie que c'est un fichier
ordinaire et que le propriétaire du processus a les droits
d'écriture sur ce fichier.
- le système libère les blocs de données, réduit la taille ` 0, mais ne modifie pas les droits.
- read
int nbcharlus = read(int d, char * tampon, int nb_à_lire);
- d : numéro du descripteur de fichier dans la table.
- tampon : tableau de caractères où sont placés les caractères lus.
- nb_à_lire : nombre de caractères à lire.
- nbcharlus : nombre de caractères effectivement lus.
Quand nbcharlus < nb_à_lire, alors fin de fichier. attente. - mode : mode d'ouverture
int open(char * f, int mode, int permis);
- Les processus
- Introduction
- un espace d'adressage (visible par l'utilisateur)
- un BCP : bloc de contrôle de processus:
- entrée dans la table des processus
- un structure appelée zone U
- la multiplicité des exécutions : plusieurs processus peuvent être l'exécution d'un même programe
- la protection des exécutions : un processus ne peut exécuter que ses propres instructions
- se fait grâce à la commande int fork (void)
- fork crée un processus-fils du processus l'ayant appelé, dont le code sera identique
- tous les processus sont creés grâce à un fork sauf le processus d'identificateur (PID) 0, qui est creé au démarrage de la machine
- le processus de PID 0 va créer un processus de PID 1 qui est l'ancêtre de tous les autres processus
- le processus de PID 1 va recueillir tous les processus orphelins.
- Format d'un fichier exécutable
- une entête qui définit l'ensemble du fichier, ses attributs
- la taille à allouer en mémoire pour les variables non initialisées
- une zone TEXT qui contient le code du programme (en langage machine)
- une section DATA (en langage machine) qui contient les données initialisées
- données diverses (icones, données pour le débugueur,...)
- Chargement d'un exécutable
- La zone U et la table des processus
- fork et exec d'un point de vue mémoire
- Le contexte d'un processus
- l'état du processus
- son mot d'état:
- valeurs des registres actifs
- compteur ordinal
- les valeurs des variables globales statiques ou dynamiques
- l'entrée dans la table des processus
- la zone U
- les piles USER et SYSTEM
- les zones de code et de données
- Commutation d'un mot d'état
- UAL
- registres dont registres spécialisés:
- accumulateur : reçoit les résultats d'une instruction
- registre d'instruction : contient l'instruction en cours
- compteur ordinal : adresse de l'instruction en mémoire
- registres d'adresse
- registres de données
- registres d'état:
- du processeur
- du processus
- le contexte d'unité centrale qui est composé des mêmes données pour tous les processus
- le contexte qui dépend du code utilisé
- adresse de sauvegarde du premier mot d'état
- adresse de changement du nouveau
- Les interruptions
- externes (indépendantes du processus) intervention de l'utilisateur, pannes...
- déroutement : erreurs internes du processeur, débordement, divisio par zéro, erreur de mémoire...(sauvegarde sur le disque de l'image mémoire : core dumped).
- appels-système : demande d'entrée-sortie par exemple
- Cascade d'interruption
- Etat et transitions d'un processus
- il sélectionne le ou les processus les plus appropriés pour un transfert hors mémoire centrale (swapout)
- il réalise ce transfert
- une fois la place suffisante libérée, le processus qui a provoqué le swapout passe en mémoire centrale (swapin)
- La table des processus
- La zone U
- Accès à la table des processus et à la zone U
- informations temporelles:
times (struct tms *buffer)
remplit la struct pointée par buffer:
struct tms
{
tms_utime; // temps utilisateur tms_stime; //temps système tms_cutime; // temps utilisateur fils tms_cstime; // temps système fils -
changement de répertoire :
chroot (const char *path)
change le répertoire racine. (définit un nouveau point de départ pour les références absolues).
chdir (const char *ref)
change le répertoire courant de travail donc la référence relative. -
récupération du PID d'un processus
getpid () : renvoie le pid du processus appelant
getppid () : renvoie le pid du père du processus appelant
getpgrp () : renvoie le pid du groupe du processus appelant
- Modification des données de la zone U
- tailles limites :
ulimit (int cmd, ...)
cmd peut prendre les valeurs suivantes :
UL_GETFSIZE : retourne la taille maximum des fichiers en blocs
UL_SETFSIZE : positionne cette valeur avec le deuxième argument -
priorité :
nice (int valeur)
permet de spécifier la priorité du programme d'exécution du processus, plus la valeur est petite, plus le processus est prioritaire. Seul le superuser peut spécifier une valeur négative.
C'est un ensemble d'octets en cours d'exécution. C'est ce qui représente l'exécution d'un programme en mémoire.
Il se compose de:
Les processus UNIX communiquent entre eux et avec le reste du système grâce aux appels-systèmes.
Création d'un processus:
Ils ont le format suivant, qui permet au noyau de les transformer en processus:
L'appel système exec permet de charger (ou de changer) l'exécutable d'un programme.

Lorsqu'on tape une commande en shell, un shell-fils est créé grâce à un fork (étape 1), puis le code de la commande est changé en mémoire par un exec() (étape 2). La commande s'exécute, et, à la fin appel de la fonction exit() (étape 3).
Tous les processus ont une entrée dans la table des processus. Mais le noyau alloue pour chaque processus une structure appelée zone U, qui contient des données privées sur le processus, auxquelles le noyau seul a accès. La table des processus permet d'accéder à la table des régions par processus, qui elle accède à la table des régions (en mémoire).
Lors d'un fork, le contenu de la table des régions est dupliqué, mais chaque régions est soit partagée ou copié. Lors d'un exec, libération des régions et réallocation de nouvelles régions.
fork() : on rajoute aux processus existants.
exec() : on supprime les processus existants.
C'est l'ensemble des données qui permettent de reprendre l'exécution d'un processus interrompu.
Il est composé de:
Pour être exécuté, un programme doit être chargé en mémoire centrale, et ses instructions une à une à l'unité centrale.
L'unité centrale:
Un processus est caractérisé par deux contextes:
Cette instruction utilise deux adresses:
Une interruption, c'est une commutation du mot d'état provoquée par le matériel.
Ce signal est la conséquence d'un évènement extérieur ou intérieur, il modifie un indicateur régulièrement testé par l'UC.
Une fois le signal détecté, il faut en déterminer la cause. On utilise pour cela unu indicateur : le vecteur d'interruption.
Trois grands types d'interruption :
EX : sous UNIX, généralement:
Si plusieurs niveaux d'interruption se présentent quand le système les consulte, c'est le niveau d'interruption qui va permettre au système de déterminer laquelle il doit traiter en priorité.
Si, pendant le traitement d'une interruption, un autre interruption se produit, et que ceci se répète, le système ne fait plus progresser les processus, ni les interruptions en cours de traitement.
On peut retarder ou annuler la prise en charge d'un ou plusieurs niveaux d'interruption.
C'est le rôle des mécanismes de masquage et de désarmement. Le masquage permet d'ignorer temporairement un niveau d'interruption. Le désarmement rend impossible le traitement d'un niveau d'interruption. Ce dernier ne s'applique pas aux interruptions de type déroutement.
liste des états:
1.le processus s'exécute en mode utilisateur
2.le processus s'exécute en mode noyau
3.le processus ne s'exécute pas mais il est éligible (= prêt)
4.le processus est endormi en mémoire centrale
5.un processus prêt mais en attente de transfert (swap) en mémoire centrale pour le rendre éligible
6.processus endormi en zone de swap (généralement le disque)
7.le processus passe du mode noyau au mode utilisateur mais il est préempté (il est prêt mais il est retiré de l'unité de traitement pour que les autres processus puissent s'exécuter)
8.naissance du processus : ni prêt, ni endormi, c'est l'état initial de tous les processus.
9.état zombie : juste après un exit, le processus est encore vivant juste le temps pour so père de récupérer les informations le concernant.
le diagramme d'état:
explication :
soit le processus est préempté -> 7, quand le processus préempté est réélu, il repasse directement en mode utilisateur -> 1
soit l'interruption est due à une E/S, endormissement du processus -> 4, à la fin de l'E/S, une autre interruption est générée, le processus est endormi en mode prêt -> 3
soit une interruption due à une erreur, terminaison du processus -> 9
Si un processus se trouve en -> 4, un autre processus a besoin de sa place mémoire, il passe en zone de swap -> 6
Une fois reçu l'interruption de réveil, il passe en -> 5
Quand suffisament de mémoire centrale sera libérée, il repassera alors en -> 3
exemple

l'ensemble de la mémoirecentrale est occupée par des processus mais le processus le plus prioritaire est en -> 5, il faut libérer donc de la place en -> 3;
libérer de la mémoire = faire passer des processus de ->3 ou ->4 en ->5 ou ->6, c'est le rôle du swappeur :
Elle se trouve dans la mémoire du noyau et contient toutes les informations auxquelles le noyau doit avoir accès.
elle contient :
-état du processus
-adresse de la zone U
-adresses : taille et localisation en mémoire (centrale, secondaire)
-UID : propriétaire du processus
-PID, PPID : identification du processus et de son père
-évènement : description de l'évènement qui réveillera le processus quand il est endormi
-priorités : utilisées par l'ordonnanceur pour sélectionner l'élu parmi les lrocessus prêts
-vecteur d'interruption : ensemble des signaux reçus mais pas encore traités
-divers : différents compteurs : temps CPU utilisé...
Une unique zone U est accessible à la fois, celle des processus en cours d'exécution:
Elle contient:
-pointeur sur la table des processus
-UID de l'utilisateur, détermine les privilèges du processus, les droits d'accès aux fichiers...
-compteur de temps utilisé par le processus (user et sstème)
-erreur, stockage de la dernière erreur rencontrée lors d'un appel système
-retour, valeur de retour du dernier appel système
-E/S, contient les structures associées aux E/S
-"." et "/" répertoire courant et racine
-limite de la taille des fichiers de la mémoire utilisable
-umask, masque de création des fichiers
Pour accéder aux donnée de la table des processus, on utilise la commande ps. Par contre, les informations de la zone U ne sont accessibles que par une réponse du processus lui-même.
On y accède par différentes commandes :
- Ordonnancement des processus
C'est la sélection dans le temps des processus pouvant accéder à une ressource
Un algorithme d'ordonnancement réalise la sélection de celui qui va obtenir l'autorisation d'utiliser une ressource (UC ou E/S).
Pour l'UC, notre but est de maximiser le débit et le taux utile de l'UC. Le débit est le nombre moyen de processus exécutés en un temps donné. Le taux utile, c'est la proportion de temps réellement utilisé pour exécuter les processus utilisateurs.
- Partage de l'U.C
- Ordonnancement sans préemption
- Algorithmes préemptifs
- Multi-level-feedback round-robin Gueues
Il doit être fait entre les processus utilisateurs mais aussi entre les autres tâches du système :
les E/S, les interruptions...
De plus, notre algorithme d'ordonnancement devra nous assurer deux choses :
exclusion mutuelle (une ressource est affectée à un processus à la fois)
absence de famine (il y a famine si un processus attend pendant un temps indéterminé l'accès à une ressource)
Pour trouver un algorithme d'ordonnancement, on se base sur deux remarques statistiques du comportement de processus :
-les processus ont tendance à basculer constamment entre phase d'E/S et phase de calcul sur l'UC.
-les processus consommant de longues périodes d'UC sont proportionnellement rares.

Eviter la famine
Un système qui ne crée pas de famine fournit toujours au processus la ressource demandée après un temps fini.
Pour les périphériques (les disques), l'ordonnancement peut se faire par une file d'attente (FIFO).
Pour l'unité centrale, on va utiliser des structures plus complètes de manière à gérer les priorités. On pourra par exemple, permettre à des processus d'éviter la file d'attente. On peut utiliser différentes structures : file, liste, arbre, en fonction de la clé de notre algorithme. (priorité simple...) Cette structure devra nous donner accès à tous les processus éligibles.
Stratégie globale d'un algo d'ordonnancement :

Les ordonnancements à court terme doivent être le plus court possible car le processus élu ne va utiliser l'UC que pendant un très court laps de temps.
-Critère de performance :
taux d'utilisation de l'UC
débit
temps réel d'exécution
temps d'attente
temps de réponse
les critères sont plus ou moins exclusifs, il faudra donc faire une sélection.
.FCFS : first come first served, peu efficace.
.SJF : shortest job first, le plus petit en premier, optimal pour le temps d'attente moyen.
à priorité : l'utilisateur donne à chaque processus une priorité et ils sont activés en fonction de cette priorit&eacue;. Il y a possibilité de famine par les processus les moins prioritaires. La solution, plus le temps passe, plus le processus devient prioritaire.
La préemption, c'est la possibilité qu'à le systè de reprendre une ressource à un processus avant que celui-ci ne l'ait libéé.
FCFS ne peut être préemptif
SJF peut l'être : si un processus plus court que celui qui est actif arrive, le processus actif est préempté, et le nouveau s'exécute.
Le round-robin (tourniquet) , particulièrement adapté aux systèmes à temps partag&eacue;. On va définir un quantum de temps d'utilisation de l'UC. La file des processus éligibles sera une queue circulaire (fifo circulaire). Tout processus nouveau est placé à la fin de la queue.
Soit le processus actif rend l'UC avant la fin de sa tranche de temps (E/S par exemple), soit il est préempté. Dans les deux cas, il est placé à la fin de la liste.
Si on a n processus, et q le quantum de temps, chaque processus est assuré d'obtenir le processeur au bout de (n-1)*q secondes au plus -> famine évitée.
le quantum de temps pose un prolème :
-si q est trop grand, round-robin revient à FCFS
-qi q est trop petit, beaucoup de préemption, le nombre de changements de contexte grandit d'où une diminution du taux utile donc processeur n fois moins rapide (pour n processus).
Une règle empirique est d'utiliser un quantum de temps tel que 80% des processus libérant naturellement l'UC avant l'expiration du quantum.
Les algorithmes à queues multiples
On différencie les processus en plusieurs classes de priorité différentes. Pour s&eacuta;lectionner un processus, le scheduler parcourt succéssivement les queues dans l'ordre décroissant des prioritées.
Un exemple de queues organisées en fonction du contenu des processus :
-processus systèmes
-processus interactifs
-processus gros calcul
-processus utilisateurs
Pour qu'un processus utilisateur soit exécuté, il faut que les autres queues soient vides.
il est possible de réaliser différents algorithmes d'ordonnancement sur les différentes queues :
un round-robin sur les processus interactifs. un fcfs pour les gros calculs en tâche de fond par exemple.
C'est le système d'ordonnancement des processus sous UNIX : plusieurs files d'attente qui matérialisent différents niveaux de priorité, et à l'intérieur de ces niveaux, on utilise un tourniquet.

Dans les listes internes au noyau, de simples files d'attente sont utilisées (avec possibilité de passer devant un processus endormi de la même liste).
Dans les processus utilisateurs, on applique la règle du tourniquet.
Il faut d'abord calculer une priorité de base qui permet de placer le processus dans la bone file d'attente.
un processus qui utilise l'UC voit sa priorité augmenter.
un processus qui libère l'UC pour une E/S ne voit pas sa priorité changer.
Plus la valeur de la priorité est grande, moins le processus est prioritaire.
Evolution de la priorité Sous BSD, le scheduler utilise l'équation suivante, tous les 4 clics d'horloge :
Puserprio = PUSER + (Pcpu/4) + 2Pnice
Pcpu : estimation du temps passé par le processus sur l'UC.
Pnice : valeur spécifiée par l'appel à nice, varie entre -20 et +20 (valeur négative réservée au superuser).
La valeur de Pusrprio augmente avec le temps d'exécution du processus donc plus le processus passe de temps sur l'UC, moins il devient prioritaire.
Les processus non exécutés deviennent forcément les plus prioritaires au bout d'un temps fini.
Pour que Pcpu ne soit pas trop pénalisante sur le long terme, Pcpu est attée par la formule suivante :
Pcpu = ((2*load)/(2*load+n)) * Pcpu + Pnice
load = nombre moyen de processus actifs pendant une minute.
Les classes de priorités :
PSWAR : 0 priorité en cours de swap
PINOD : 10 priorité en attendant lecture d'information SGF
PRIBIO : 20 priorité en attente d'E/S disque
PZERO : 25 priorité limite
PWAIT : 30 priorité d'attente de base
PSLEP : 40 priorité d'attente d'un évènement
PUSER : 50 priorité de base pour les processus utilisateurs.
L'ordre des priorités est très important. Les processus en attente d'un disque doivent être prioritaires par rapport aux processus en attente d'un buffer, car ils peuvent libérer un buffer.
Si la priorité était inversée, possibilité d'interblocage ou d'attente très longue.
- Aperçu de la programmation systè en C
- on bufferise les commandes d'écriture et de lecture et on
fait un accès disque uniquement pour une quantité de
données raisonnable.
C'est un ensemble de structures de données et d'algorithmes qui permettent de minimiser le nombre d'accès disque.
Le buffer cache a un rôle très important:

Une INFORMATION est une donnée en arithmétique binaire (0 où 1), au niveau le plus bas de la machine.
Pour s'en sortir, il est nécessaire de connaître les principales puissances de 2. Les bits sont indicés de la gauche vers la droite. exemple :
(110101)2 -> 25 +24 +22 +20 = 53
La méthode la plus simple reste la méthode de la division
Il s'agit tout simplement d'inverser la valeur de chaque bit.
principe: On inverse les valeurs de chaque bit puis on rajoute 1.
le code ASCII est codé sur 7 bits : 128 caractères possibles.
Cartes perforées.
16 bits
=> 38885 caractères
Contient tous les caractères du monde.
Standard de JAVA.
http://www.unicode.org
Un ordinateur:c'est un ensemble de composants d'E/S, la CPU...Le matériel est utilisé par le logiciel.
3 types de logiciels:
-logiciel d'application (utilisable par l'utilisateur...)
-logiciel de développement (qui construit les logiciels d'application)
-logiciel d'exploitation
Le système d'exploitation (SE) permet de s'affranchir de la gestion des périphériques par exemple, de la mémoire et des ressources en général. Le SE est l'intermédiaire entre la machine et l'utilisateur.

Les logiciels de développement ainsi que le SE constituent une machine virtuelle débarassée des contraintes matérielles.
Le SE coordonne toutes les tâces nécessaires au bon fonctionnement de l'ensemble des composants matériels. Il assure la gestion des ressources disponibles. Il permet la communication entre l'utilisateur et la machine de façon plus ou moins conviviale grâce à une interface adaptée.
Le SE UNIX est écrit dans un langage de haut niveau:le C. Il comprend une interface simple mais puissante:le shell. Ce système est multiutilisateur et multitâche. UNIX comprend également un système de fichiers hiérarchiques et cache complètement l'architecture de la machine à l'utilisateur.
-ouverture par la diffusion des sources
-langage de haut niveau
-facilité de communication inter-système
-langage de commande puissant
-interface graphique X11
-multiutilisateurs
-parallélisme.
-fragilité du système de gestion de fichiers
-gestion des interruptions:pas de temps réel.
C'est une architecture en couches.
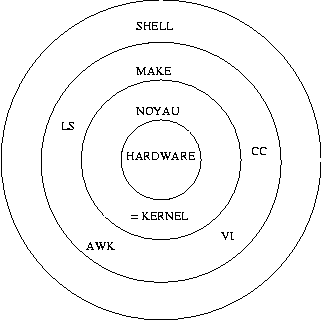
-les utilisateurs communiquent avec la couche la plus haute.
-le programmeur en fonction de ses besoins, va utiliser les couches plus ou moins profondes.
-on peut utiliser chaque couche sans savoir ce qui se passe dans les couches inférieures.
-plus une application est écrite dans une couche haute, plus elle sera portable.
-si la rapidité est plus importante que la portabilité, il vaut mieux utiliser les couches les plus basses.

C'est un outil de manipulation des fichiers et de la structure d'arborescence sur disque. Il permet sous UNIX de conserver la pérénnité des informations vitales du système: tous les objets importants (mémoire, terminaux, périphériques,...) y sont référencés.
De plus, il permet d'utiliser les fichiers de manière transparente en ce qui concerne les problèmes d'accès(partage, droits,...)
C'est une unité de base.
C'est l'unité logique de base du SGF.
Les fichiers ne sont pas typés :
-
Une inode définit le fichier par:
Deux grandes familles :
Disque logique
